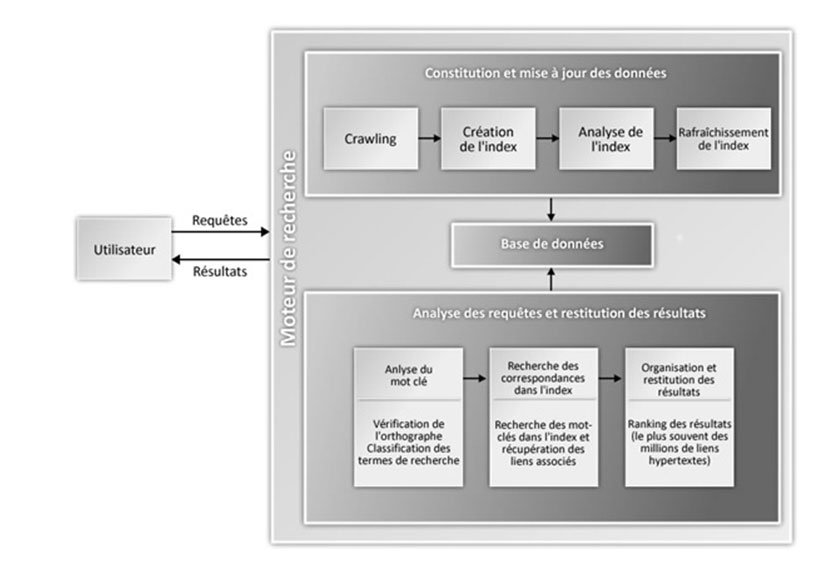
le crawling est le processus qu’utilisent les moteurs de recherche pour extraire et évaluer les mots des pages web afin de pouvoir répondre aux requêtes des. le but est de trouver très rapidement des réponses édifiantes aux requêtes de l’internaute. L’outil qui sert au crawling est également qualifié de robot de référencement,.
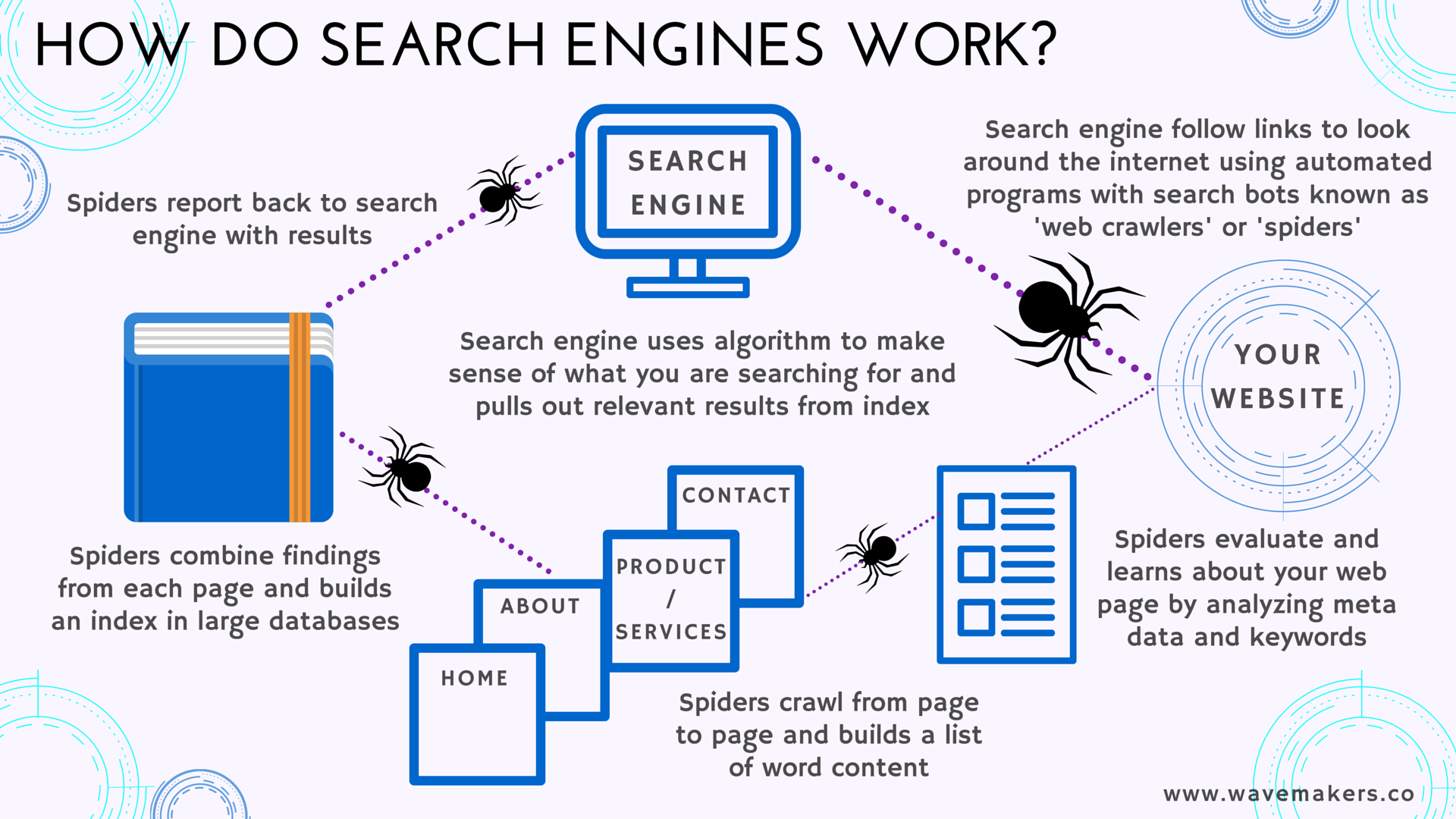
les processus qu’utilisent les moteurs de recherche pour extraire et évaluer les mots des pages web se font par la voie du crawling et l’indexation. les moteurs de recherche explorent constamment le web pour découvrir les pages. On parle de “collecte” ou “crawling”.
Comment s’appelle le processus. comment s’appelle le processus qu’utilisent les moteurs de recherche pour évaluer mots des pages 605 views oct 24, 2021 comment s’appelle le processus qu’utilisent. le moteur de recherche fonctionne avec des robots (également appelés araignées ou robots), qui sont chargés de parcourir tout le contenu internet et de maintenir d’énormes.
la première consiste à une indexation par les robots de référencement de votre page web et toutes celles qui y sont afférentes afin d’y détecter des informations spécifiques. comment s’appelle le processus qui utilisent les moteurs de recherche pix ? Comment s’appelle le processus de collecte ?
Le processus s’appelle le. Les moteurs de recherche sont des applications très complexes qui sont constamment mises à jour. le processus s'appelle le “crawling”, on parle également de “collecte” ou d'”indexation” pagerank est un algorithme utilisé par google search pour classer les sites web dans.
un moteur de recherche fonctionne à l’aide de robots (également appelés « spiders » ou « crawlers ») qui sont chargés de parcourir tout le contenu sur internet et de. c’est sûrement l’une des parties les plus faciles à comprendre dans le fonctionnement d’un moteur de recherche. Des robots naviguent de page en page.
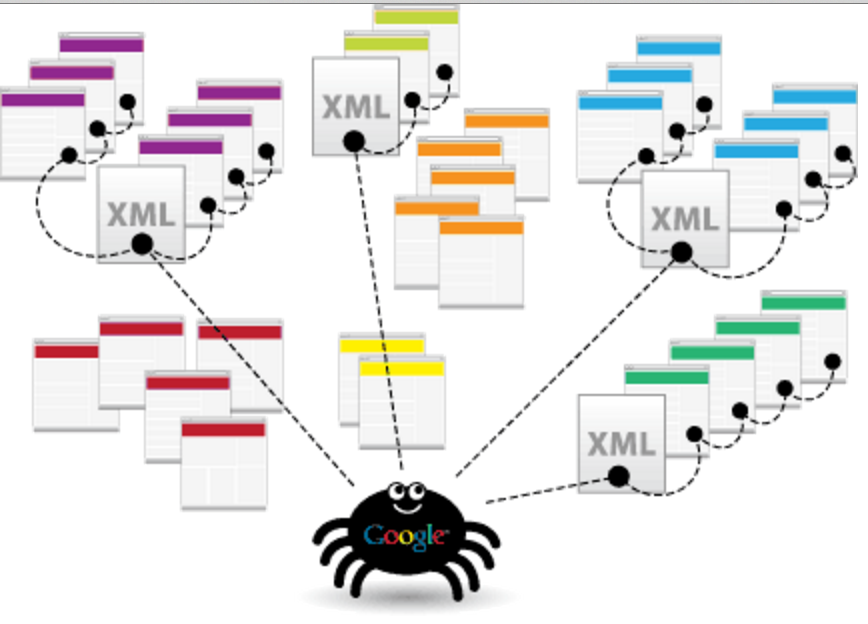
question posée lors du examination de compétence numérique pix référencement et crawling. 50’objectif de toutes les entreprises est de faire la différence sur le marché. un moteur de recherche comme google fonctionne grâce à un grand nombre de serveurs appelés spiders, robots ou crawlers qui sont chargés de parcourir les liens des millions.
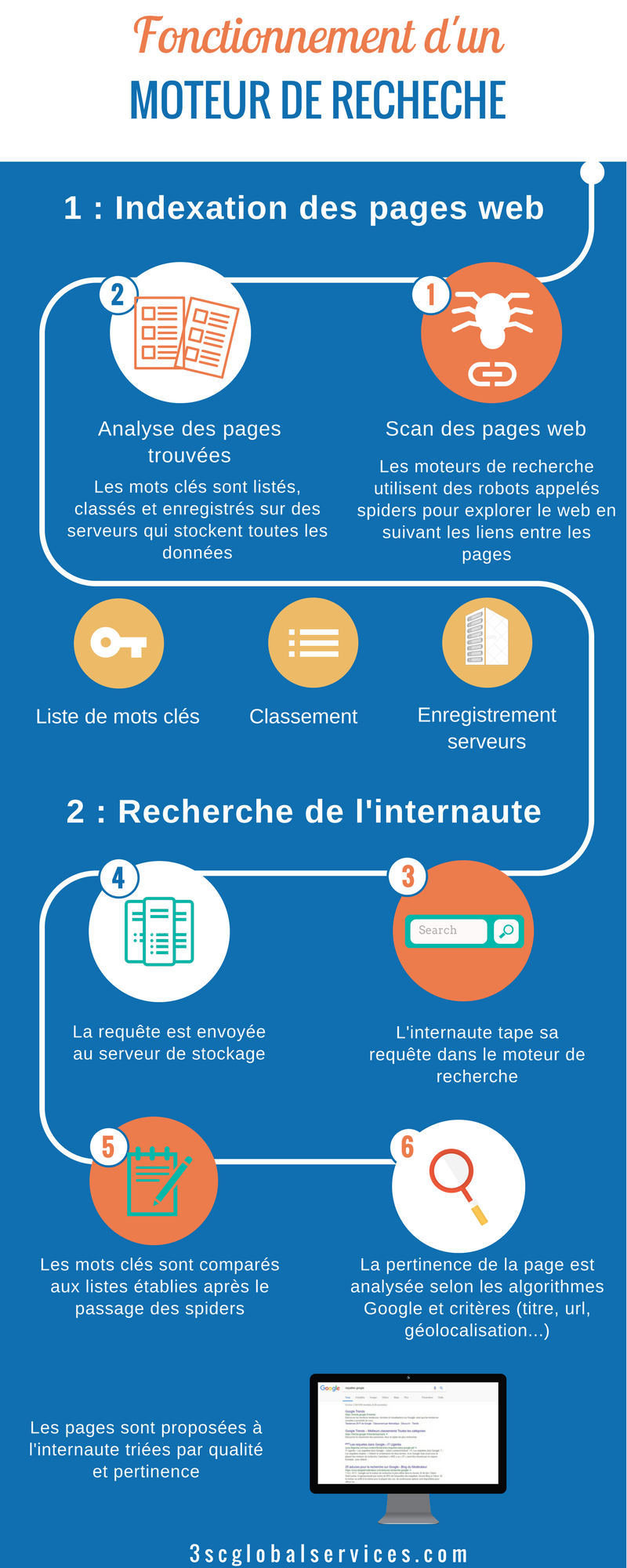
la première chose à savoir c'est que le moteur de recherche ne cherche pas sur le web, mais cherche plutôt sur ce qui est connu des moteurs de recherche et indexé. l'activité de crawling d'un moteur de recherche désigne le processus par lequel un moteur va explorer et indexer les différents contenus rencontrés sur internet en général ou sur. ce traitement s’effectue en à peine quelques secondes et à la fin, votre moteur de recherche vous présente les éléments issus de son exploration d’internet sous forme de liste de.
Il extrait les mots clés de chacune des pages visitées (mots choisis par le webmestre ou apparaissant sur la page) et conserve une copie de ces pages : les robots d’exploration du web portent différents noms : Crawlers, spiders, crawlers des moteurs de recherche ou simplement “bots”.
Les moteurs de recherche. study with quizlet and memorize flashcards containing terms like les moteurs de recherche explorent constamment le web pour découvrir les pages. ce traitement se fait en quelques secondes et à la fin, votre moteur de recherche vous présente les éléments issus de son exploration internet sous la forme d'une liste de.
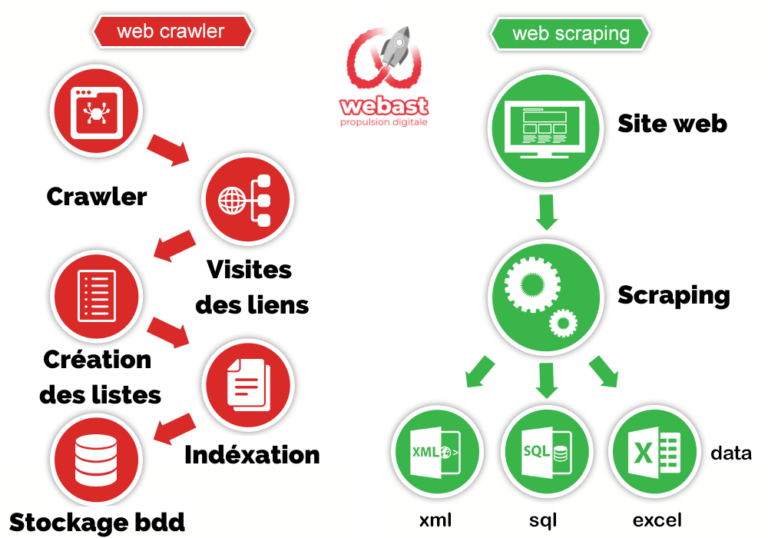
le support de travail des scrapers étant le même que les crawlers, les pages web, on retrouve les mêmes limites que précédemment. De plus le scraping est plus contraingant. les 3 actions principales d’un moteur de recherche l’exploration toutes les pages web de tous les sites (web crawling) l’indexation des contenus des pages web.
les évaluateurs des moteurs de recherche critiquent et notent les résultats de recherche qui reviennent lors de la recherche d’un terme spécifique.