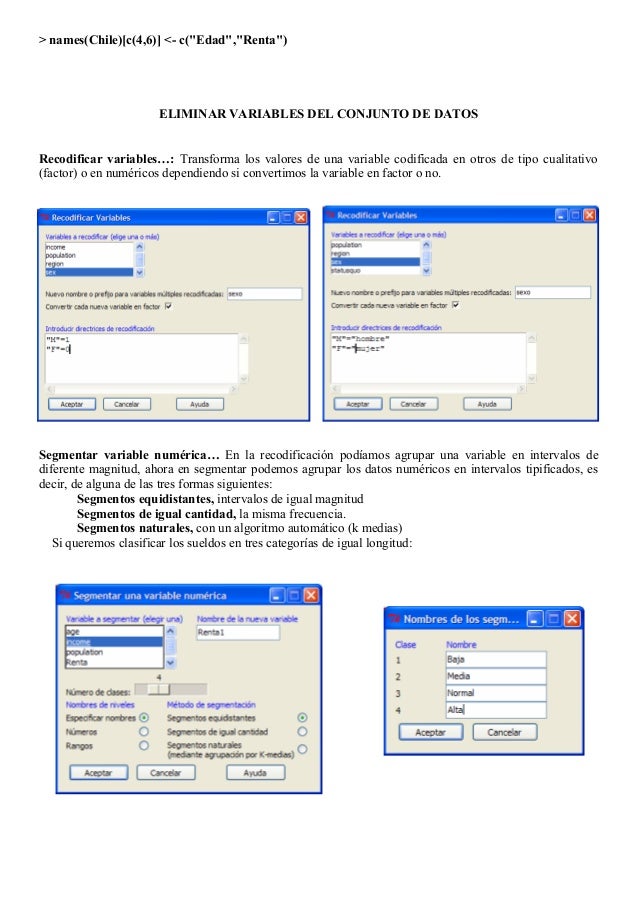
Eliminar columnas por nombre. El siguiente código muestra cómo eliminar columnas de un marco de datos por nombre: En r [,] se usa para hacer subconjuntos, que es el nombre técnico de lo que quieres hacer.
Como en este caso estás trabajando con un data. frame, que es una estructura de datos bidimensional (filas y columnas) usas la coma dentro de los corchetes para hacer subconjuntos de filas (primera posición) y columnas (segunda posición). El resto tienen huecos, siendo f6 la que más nulls tiene con un 44,83% de datos faltantes. Si realizáramos un na. omit() “a pelo”, tal como se indicó al principio, prácticamente nos quedaríamos sin filas en el dataframe, ya que casi todas las filas contienen null en alguna columna.
Por ello, vamos a realizar una limpieza de variables. The r programming language offers two helpful functions for viewing and removing objects within an r workspace: List all objects in current workspace rm():
Remove one or more objects from current workspace this tutorial explains how to use the rm() function to delete data frames in r and the ls() function to confirm that a data frame has been deleted. Usar anti_join () el método anti_join está disponible en el paquete dplyr. Entonces tenemos que instalar el paquete dplyr primero.
Para instalar podemos usar el método install. package (), y tenemos que pasar el nombre del paquete como parámetro. Para importar el paquete al entorno r, necesitamos usar la función library (). Busque un código de ejemplo o una respuesta a la pregunta «cómo quitar filas con inf de un dataframe en r»?
Ejemplos de diferentes fuentes (github,stackoverflow y otros). Cómo quitar filas con inf de un dataframe en r. Cómo quitar filas con.
2. 1 crear un data frame vacío en r. 3 accediendo a los datos del data frame. 3. 1 acceso directo utilizando la función attach.
4 añadir columnas y filas a un data frame. 5 eliminar columnas y filas de un data frame. 6 ordenando y filtrando datos de un data frame en r.
6. 1 ordenar data frames. 6. 2 filtrar data frames. Este proceso también se denomina subconjunto en lenguaje r.
Para eliminar una fila, proporcione el número de fila como índice para el marco de datos. La sintaxis se muestra a continuación: Mydataframe es el marco de datos.
Son los índices separados por. Puedo filtrar por userid para ver quién lo ha tomadodemasiadas veces y estoy buscando una manera de eliminar fácilmente esas filas del conjunto de datos. En este caso, el id de usuario 52118284 lo tomó tres veces y el segundo intento debe eliminarse.
Si es legible como la otra solución eso es mejor. Respuestas 2 para la respuesta № 1. Eliminar na con base r.
El siguiente código muestra cómo usar complete. cases () para eliminar todas las filas en un marco de datos que tienen un valor faltante en cualquier columna: # eliminar todas las filas con un valor faltante en cualquier columna df [ complete. cases (df),] puntos ayuda a rebotes 1 12 4 5 3 19 3 7. Cómo eliminar filas con inf de un marco de datos en r;
Calcular las medias de las filas en un subconjunto… funciones de búsqueda usando grep sobre múltiples… en r, función de coincidencia para filas o columnas… selección de varias columnas/filas pares o impares… aplicar la función a cada elemento en data. frame y… marco de datos. En donde df es el dataframe, text es la variable que contiene el párrafo y la cadena de texto es aquel dato por el cual queremos filtrar. Lo que se puede hacer es combinar filter con alguna función para encontrar textos en otros, por ejemplo grepl ():
Library (tidyverse) data. frame (text=c ('lorem ipsum dolor sit amet', 'consectetur. Hay varias opciones para eliminar una o más columnas con dplyr::select () y algunas funciones auxiliares. Las funciones auxiliares pueden ser útiles porque algunas no requieren nombrar todas las columnas específicas para descartar.
Eliminar columnas de un dataframe forma simple. La solución de wen es realmente agradable e intuitiva. Aquí hay una alternativa, llamando repeat en df. values.
Df code role persons 0 123 janitor 3 1 123 analyst 2 2 321 vallet 2 3 321 auditor 5 pd. dataframe(df. values. repeat(df. persons, axis=0), columns=df. columns) code role persons 0 123 janitor 3 1 123 janitor 3 2 123 janitor 3 3 123 analyst 2 4 123 analyst 2 5 321 vallet 2 6. Tengo un conjunto de datos con 11 columnas con más de 1000 filas cada una. Las columnas fueron etiquetadas v1, v2, v11, etc.
Reemplacé los nombres con algo más útil para mí usando el comando. Cómo eliminar la primera fila de un dataframe en r? Tengo un conjunto de datos con 11 columnas con más de 1000 filas cada una.